Trim and Map Sanger Reads
The workflow performs the following tasks:
- Reads a set of Sanger sequencing reads from ABI files.
- Trims the ends of the reads based on quality value.
- Filters out short trimmed reads.
- Maps the filtered, trimmed reads to a reference sequence.
You can adjust the workflow parameters:
- Quality threshold for trimming.
- Minimum read length. If the length of a trimmed read is less than the minimum value, the read is filtered out.
The output data are:
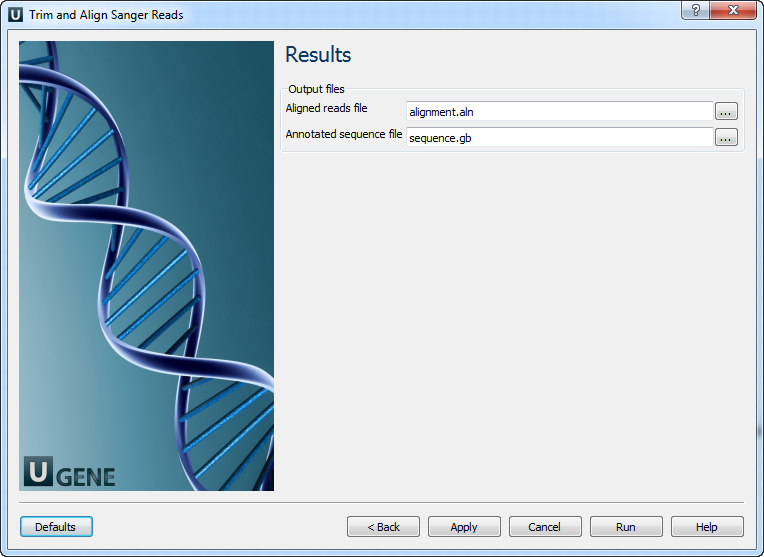
- A multiple sequence alignment file. The first sequence of the alignment is the reference, and the other sequences are the reads.
- An annotated reference sequence file. The annotations represent the mapped reads.
How to Use This Sample
If you haven’t used workflow samples in UGENE before, refer to the “How to Use Sample Workflows” section of the documentation.
Workflow Sample Location
The workflow sample “Trim and Map Sanger Reads” can be found in the “Sanger Sequencing” section of the Workflow Designer samples.
Workflow Image
The opened workflow appears as follows:
Workflow Wizard
The wizard has four pages.
Reference Sequence: On this page, you must input the reference sequence.
Input Sanger Reads (ABI Files): On this page, you must input ABI file(s).
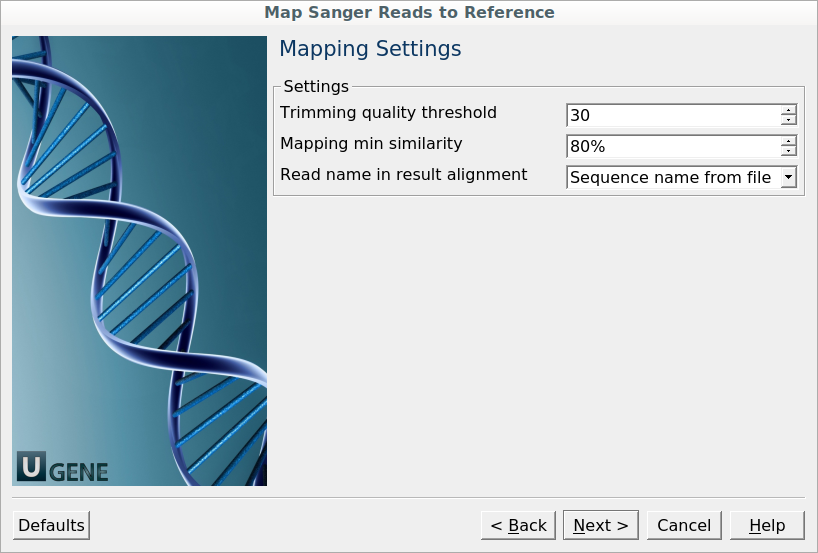
Mapping Settings: On this page, you can modify mapping settings.

The following parameters are available:
Trimming quality threshold: The quality threshold for trimming.
Mapping minimum similarity: Reads with a similarity to the reference less than the specified value will be ignored.
Read name in the resulting alignment: Reads in the resulting alignment can be named either by the sequence names in the input files or by the input file names. For example, if the sequences have the same name, set this value to “File name” to distinguish the reads in the resulting alignment.
Results: On this page, you can modify output file settings.